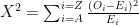If you need a reminder on how the Caesar Cipher works click here.
The Caesar Cipher is a very easy to crack as there are only 25 unique keys so we can test all of them and score how English they are using either Chi-Squared Statistic or N-Gram Probability.
Example
Ciphertext of “RCZIOCZXGJXFNOMDFZNORZGQZVOOVXF”
Shift | Decrypted Text | Chi-Sq Score 1 QBYHNBYWFIWEMNLCEYMNQYFPYUNNUWE 201.327499 2 PAXGMAXVEHVDLMKBDXLMPXEOXTMMTVD 599.489345 3 OZWFLZWUDGUCKLJACWKLOWDNWSLLSUC 267.058510 4 NYVEKYVTCFTBJKIZBVJKNVCMVRKKRTB 325.267580 5 MXUDJXUSBESAIJHYAUIJMUBLUQJJQSA 775.163340 6 LWTCIWTRADRZHIGXZTHILTAKTPIIPRZ 434.880892 7 KVSBHVSQZCQYGHFWYSGHKSZJSOHHOQY 554.916606 8 JURAGURPYBPXFGEVXRFGJRYIRNGGNPX 340.923863 9 ITQZFTQOXAOWEFDUWQEFIQXHQMFFMOW 1012.384679 10 HSPYESPNWZNVDECTVPDEHPWGPLEELNV 115.358434 11 GROXDROMVYMUCDBSUOCDGOVFOKDDKMU 91.670467 12 FQNWCQNLUXLTBCARTNBCFNUENJCCJLT 283.701596 13 EPMVBPMKTWKSABZQSMABEMTDMIBBIKS 194.299832 14 DOLUAOLJSVJRZAYPRLZADLSCLHAAHJR 385.733449 15 CNKTZNKIRUIQYZXOQKYZCKRBKGZZGIQ 1520.292006 16 BMJSYMJHQTHPXYWNPJXYBJQAJFYYFHP 801.523128 17 ALIRXLIGPSGOWXVMOIWXAIPZIEXXEGO 603.683962 18 ZKHQWKHFORFNVWULNHVWZHOYHDWWDFN 280.874579 19 YJGPVJGENQEMUVTKMGUVYGNXGCVVCEM 269.610988 20 XIFOUIFDMPDLTUSJLFTUXFMWFBUUBDL 176.849244 21 WHENTHECLOCKSTRIKESTWELVEATTACK 51.921327 22 VGDMSGDBKNBJRSQHJDRSVDKUDZSSZBJ 460.236803 23 UFCLRFCAJMAIQRPGICQRUCJTCYRRYAI 262.108135 24 TEBKQEBZILZHPQOFHBPQTBISBXQQXZH 1373.411997 25 SDAJPDAYHKYGOPNEGAOPSAHRAWPPWYG 90.715517
As you can see the lowest Chi-Squared value is 51.921327, which was using a shift of 21. If you read the decrypted text for a shift of 21 you can indeed see that it is English. Hence cipher has been broken!
WIP
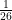 of appearing, the Index of Coincidence is also
of appearing, the Index of Coincidence is also  ).
).