
For starters a n-gram is a group of n letters – particular sizes are often refered to as: 1 a unigram, 2 a bigram/digram, 3 a trigram, 4 a quadgram and 5 a quintgram.
In a language there is certain n-grams that are much more common than others, the quadgram “THER” has a much greater probability than “DOXW”. So if we were to split text up into all the n-grams making it up the text and multiply the probabilities of each n-gram together, we would get the probability of that specific piece of text being a certain language.
LOOKOUT contains 4 quadgrams LOOK, OOKO, OKOU and KOUT
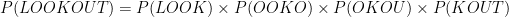
As the text gets longer, the probability gets even smaller, so small that numerical underflow occurs as there are so many zeros in the decimal place that an accurate representation can’t be stored in 64 bits. The number basically become 0.
To get round this problem we log the probability. This makes the numbers more manageable, normally in the range of 0 to -2000. This is because the probability of the text is the product of all the probabilities of individual each n-gram. So using the log rule 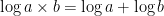
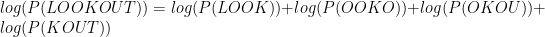
To first the probabilities of each quadgram needs to be determined
CABCD is the number of times the particular quadgram occurs
N is the total number of quadgrams in the list
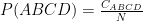
You can find lists of quadgram frequency online or create your own using large samples of text. This can have its advantages – if you create your statistics from a sample of text similar to what you are trying to score this can give better results.