
Index of Coincidence is the probability that when selecting two letters from a text (without replacement), the two letters are the same. For a random piece of text with every letter having a chance of 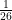

If the frequency of the letters are known and the sum of the frequencies is 1 then this formula can be used to calculate Index of Coincidence for a particular language.
Fi is the frequency, in decimal form (10% = 0.1), of a letter in your text.

For for a generic piece of text written in English the Index of Coincidence is 0.0667, it is different for each language as the letter frequencies are different…
| Language | Index of Coincidence |
| English | 0.0667 |
| French | 0.0694 |
| German | 0.0734 |
| Spanish | 0.0729 |
| Portuguese | 0.0824 |
| Turkish | 0.0701 |
| Swedish | 0.0681 |
| Polish | 0.0607 |
| Danish | 0.0672 |
| Icelandic | 0.0669 |
| Finnish | 0.0699 |
| Czech | 0.0510 |
Values for this tabled created from the frequencies from Wikipedia. The values are for letters A-Z other letters such as ‘á’ or ‘â’ are considered to be the same as ‘a’, ‘ü’ or ‘ú’ are considered to be the same as ‘u’ etc…
However if you want to figure out the index of coincidence for a particular piece of text this formula can be used.
Ci is the count, of a letter in the text.
Li is the total number of letters in the text.

If a letter does not appear more than once then is does not need to be involved in the calculation as when Ci is 1 or 0, Ci x (Ci – 1) will equal 0;
Example: ‘WHENTHECLOCKSTRIKESTWELVEATTACK’ Text length = 31
| Letter | Count (Ci) | Ci(Ci – 1) |
| A | 2 | 2 |
| C | 3 | 6 |
| E | 5 | 20 |
| H | 2 | 2 |
| K | 3 | 6 |
| L | 2 | 2 |
| M | 0 | 0 |
| S | 2 | 2 |
| T | 5 | 20 |
| W | 2 | 2 |
| Total | 31 | 62 |

This value is reasonably close to the expected Index of Coincidence value of English (0.0667). It is also much higher than that the expected Index of Coincidence of random text (0.0385) suggesting that this text is not random.
The larger the Index of Coincidence the more likely that there is some sort of language structure behind text. For example the Vigenère Cipher has an average Index of Coincidence of 0.042 – suggesting that the text is not random, which it is not.